國立臺灣大學公衛學院「健康數據拓析統計研究所」碩士班獲教育部同意於111年9月增設,於112學年度開始招生入學,並於111年9月於公衛學院成立健康數據拓析統計研究所籌備處。
傳統的統計學(statistics)其研究主題主要針對機率及統計的各項議題如隨機變數、抽樣分佈、假說檢定、估計理論、大樣本方法、迴歸分析及統計建模等等進行理論上的研究,許多大學也都有設立理論導向的統計研究所,並以上述主題為主要發展目標。然而,實務問題的迫切需求,會刺激統計學的全新發展,例如工程統計、財務統計、以及目前統計學主要研究領域之一的健康數據拓析統計(Health Data Analytics and Statistics)。健康數據拓析統計主要是由醫學及公共衛生的研究所面臨的實際問題以刺激其發展的統計領域。當今健康數據拓析統計學所探討的主要議題如下,皆值得深入研究、改良、並進一步發展。
1. 體學數據拓析統計
自從人類基因圖譜完整定序以來,各種體學(omics)的研究方興未艾,如基因體學(genomics)、表觀基因體學(epigenomics)、轉錄體學(transcriptomics)、蛋白質體學(proteomics)、代謝體學(metabolomics)、微生物基因體學(microbiomics)、暴露體學(exposomics)、等等。體學資料特色為大p小n(變數多但樣本數小)。因此要發展特別的統計方法來處理,比如各種高效能的多重檢定校正方法、集合眾多變數以提升檢定力的方法、以及考量基因調控(gene regulation)及基因網路(gene network)的生物資訊(bioinformatics)演算法、等等。體學資料種類繁多且經常來自不同的分析平台(platform),如何進行統整分析,亦是統計方法學的挑戰。體學數據拓析除了著重跨體學(cross-omics)、跨物種(cross-species)及跨平台(cross-platform)的研究外,更重要的是能夠進行跨領域(cross-discipline)的合作。體學資料拓析除了統計、數學、資訊、醫工、等等,乾實驗室(dry lab)的方法外,必須能夠跨領域結合生命科學及基礎醫學(如細胞生物學及分子生物學)的濕實驗室(wet lab)的方法,進行有關功能、機轉、調控、及人體健康效應的探討,才能做出重大科學貢獻。
2. 健康大數據拓析統計
健康大數據,如全球疾病負擔(global burden of disease)資料、癌症登記資料、全民健保資料、環境監測資料(如空氣污染、土壤重金屬污染)、等等,皆有待進一步發展適切的統計方法。比如,疾病發生率死亡率長期趨勢及未來預測的年齢年代世代模型(age-period-cohort model)、族群癌症存活(population-based cancer survival)研究為克服死因分類錯誤之相對存活分析(relative survival analysis)、全民健保研究校正未測量干擾因子的傾向分數(propensity score)方法、克服不死時間偏差(immortal time bias)的研究設計及統計方法、等等。環境監測資料則要發展時空模型,結合時間序列分析(time series analysis)及空間分析如克里金法(kriging)及土地利用迴歸(land-use regression)。
3. 健康物聯網拓析統計
健康物聯網(HIoT, Internet of Things on Health)對健康照護將產生革命性的影響。健康物聯網聯結電子病歷資料、醫療影像資料、移動醫療資料、穿戴式裝置健康監測資料、居家監控資料等等,有待進一步發展適切的統計方法,比如文字探勘(text mining)、張量學習(tensor-based learning)、降維度(dimension reduction)方法、深度學習(deep learning)、推薦系統(recommender system)等AI方法與統計學結合。健康物聯網拓析統計亦需要利用雲端運算(cloud computing)技術以及網路拓析(network analytics)的方法。這些皆有賴統計、數學、資訊、醫工、臨床醫學及公共衛生的跨領域合作,提升遠距醫療照護及居家看護的品質、整合資源減少醫療實體負擔。
4. 病因及致病機轉研究方法
慢性疾病如癌症、心血管疾病等之病因複雜,經常牽涉到基因與環境眾多因素間複雜的協同(synergy)、拮抗(antagony)、與中介(mediation)關係。未知或未測量的因子所可能造成的干擾作用(confounding),更對病因與致病機轉的釐清造成極大的挑戰。因果推論的統計方法,比如反事實潛在結果模型(counterfactual potential outcome model)、因果圓派模型(causal-pie model)、結構方程式模型(structural equation model)、以及孟德爾隨機指派(Mendelian randomization)方法、等等,近年來在病因及致病機轉的釐清,取得了不錯的進展。
5. 疾病自然史及篩檢、診斷、預後研究方法
慢性疾病以癌症為例,其自然史包括癌細胞的生成、症狀的產生、診斷、治療、至康復、失能、乃至死亡之整個歷程。疾病的篩檢係針對可檢驗臨床前期(detectable preclinical period),然而不同個案期程長短不依,因而造成前置期偏差(lead-time bias)及長度偏差(length-time bias)等問題,需要特別的統計方法解決。篩檢成效的評估亦仰賴進階的統計模型,如馬可夫轉移模型(Markov transition model)、及多階段致癌模型(multistage carcinogenesis model)、等等。診斷工具的評估除了傳統的敏感度(sensitivity)及特異度(specificity)外,亦仰賴統計學方法,如接收者操作特徵曲綫分析(ROC curve analysis)、決策曲綫分析(decision curve analysis)、等等。疾病預後方面更需要發展統計方法,如存活資料迴歸樹(regression tree for survival data)、失能調整存活分析(disability-adjusted survival analysis)、等等。
6. 傳染病數理模式
新冠肺炎疫情造成公共衛生、社會及經濟之巨大衝擊。傳染病資料如流行曲綫(epidemic curve)、點圖(spot map)、接觸追蹤(contact tracing)、社會網絡(social network)等等之分析,能初步闡釋傳染病之流行特徵。傳染病之數理模式,如易感曝露感染復原模型(susceptible-exposed-infected-recovery model)、個體為本模擬(agent-based modeling)、等等,可以預測傳染病未來可能之流行方式,也可評估各種管控方案(如社交距離保持、接觸追蹤、隔離、封鎖)的效果。
7. 臨床醫學及公共衛生觀察性硏究方法
觀察性研究是臨床醫學及公共衛生常用的研究設計方法。觀察性研究設計,如世代追蹤硏究(cohort study)、病例對照硏究(case-control study)、唯病例硏究(case-only study)、病例世代研究(case-cohort study)、病例雙親硏究(case-parents study)、雙胞胎研究(twin study)、家族硏究(family study)、系譜研究(pedigree study)、等等,常易產生各種偏差、如選擇性偏差(selection bias)、資訊偏差(information bias)、及干擾偏差(confounding bias)。值得研究者持續發展研究設計及資料分析的統計方法以改良之。
8. 臨床試驗及公共衛生介入計劃評估方法
臨床試驗研究提供醫療照護成效的嚴謹評估。第一期至第四期的臨床試驗,皆牽涉到専門的統計方法,包括計量設定(dose finding)、樣本數計算(sample size calculation)、隨機指派方式(randomization method)、對照組選擇(control selection)、等等,值得深入探討。公共衛生介入計劃,經常無法採取隨機分派方式進行評估,有賴特別的統計方法,如雙重差分硏究法(difference-in-difference study)、中斷性時間序列分析(interrupted time series analysis)、等等。
9. 醫學及公共衛生統合分析及決策分析
統合分析及網絡統合分析(network meta-analysis),統整眾多硏究成果,為實證(evidence-based)及精準(precision)醫學/公共衛生學之基礎。決策分析及網絡決策分析(network decision analysis)則能權衡成本和效益,提供研擬臨床決策準則及公共衛生政策之參考。統合分析及決策分析的統計方法值得深入硏究。此外,貝氏統計(Bayesian statistics)在健康數據拓析統計各領域都扮演舉足輕重的角色,值得大力推展。
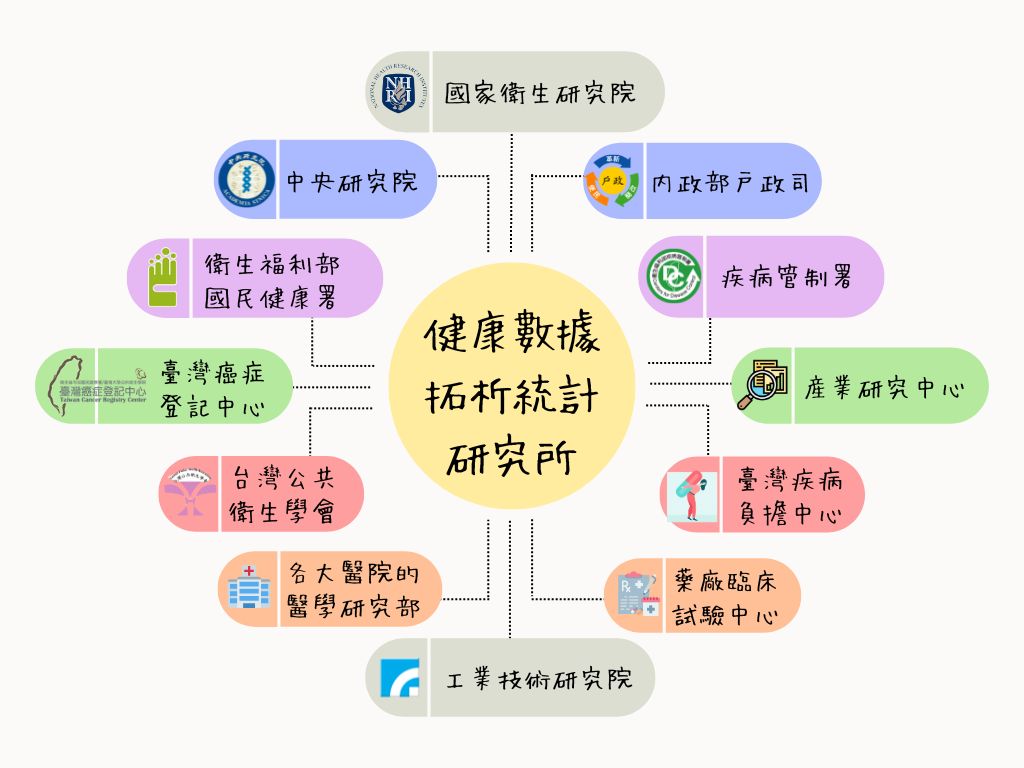
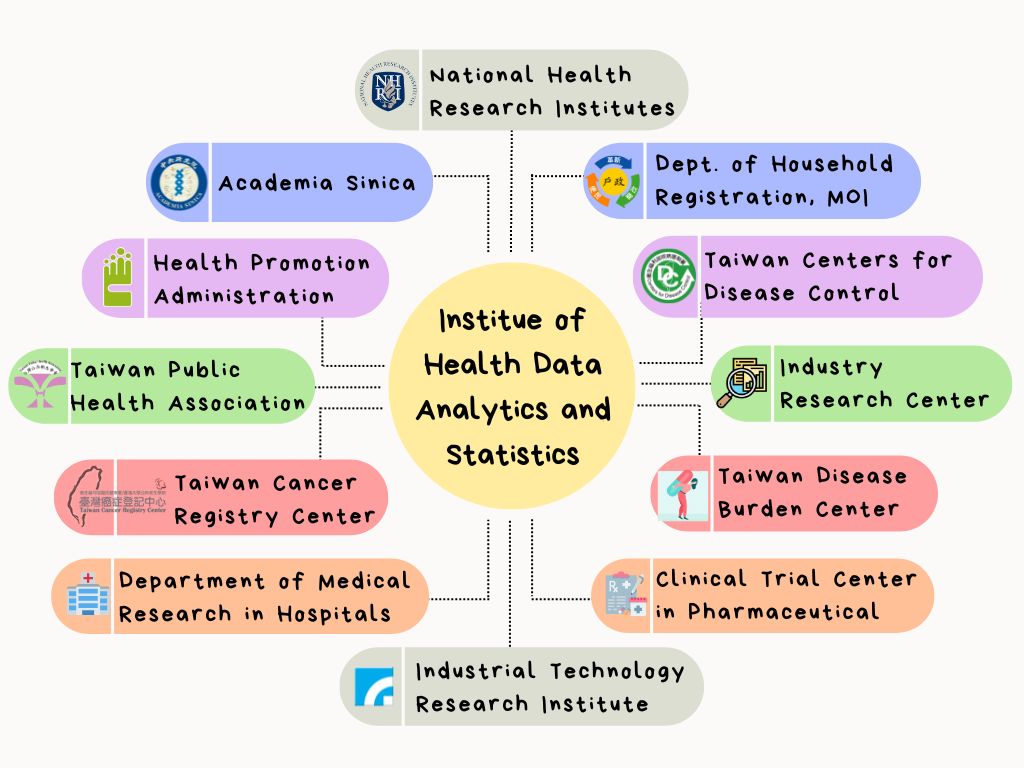
本所目前的研究夥伴有中央研究院、衛生福利部國民健康署、臺灣癌症登記中心、台灣公共衛生學會、各大醫院的醫學研究部、工業技術研究院、藥廠臨床試驗中心、產業研究中心、臺灣疾病負擔中心、疾病管制署、內政部戶政司、國家衛生研究院等如下圖,本所也支援健康大數據學分學程。